


Lately, there have been numerous discussions within the Cloud Native community and at various global conferences about eBPF. This widespread interest makes it a topic worthy of exploration and discussion. Traditionally, eBPF is an acronym for "Extended Berkley Packet Filter", and as the name suggests, it is an extended version of the Berkeley Packet Filter (BPF), which itself has historical significance. Now, you might wonder if this is a new technology. The answer is, not exactly. BPF is a technology with origins dating back a few decades, tracing its roots to 1993 in the BSD community, where it was initially designed to deliver high-speed packet filtering capabilities. Over the years, it has undergone substantial evolution, culminating in its integration into the Linux kernel. In 2014, it achieved widespread recognition and adoption thanks to groundbreaking additions, such as the verifier, eBPF maps, helper functions, and the BPF system call, among others.
Today, it transcends its original scope as a term, offering capabilities that extend far beyond mere packet filtering, with a vast array of potential use cases. Consequently, the original acronym has become obsolete. Notably, prominent companies like Facebook, Google, Netflix, and many others have embraced eBPF as a critical technology underpinning their observability, networking, and security solutions in production environments, tailored to meet their specific requirements. "In this blog, we will explore various concepts and use cases of eBPF. However, let's take a moment to retrace our steps and understand the underlying "Day 2" challenges from a different perspective.
Problem statement.
Understanding from a Networking point of view.
A few months ago, I was looking for different Observability solutions which could potentially provide information at more granular level like packet tracing and related solutions, which was the requirement for a project I was engaged in. Initially, I found that in Linux, we can establish complex networks directly on the host, using virtual interfaces and network namespaces. Usually, if there is an issue with L3 routing, MTR might offer some assistance. However, when it's a more fundamental problem, then one has to manually inspect interfaces, bridges, network namespaces, iptables, and employ tcpdumps to gain insights. Trust me, most of the time, this process can feel way more overwhelming, particularly with limited knowledge of network setup for large systems :)
What's needed is a tool that can provide insights like, "Hey, I've traced your packet, It followed this specific path through this particular interface within this designated network namespace." Alternatively, if the tool could tell us issues, like: If there is a problem in network communication, what is the underlying cause of it? Is it related to DNS? Is it potentially linked to application or network-related variables?
In addition, if there is a possibility that somehow we can look for queries like identifying service-specific problems within the last 'x' minutes or pinpointing services that have recently faced timeouts in connections or what is the p99/p95/p50 of a particular HTTPS request/response within a service. They would enhance our capacity to gain valuable insights into network performance and effectively troubleshoot potential issues and are like a cherry on top of the cake. Therefore shifting to the kernel's perspective could prove beneficial, where network namespaces are merely labels instead of containers, and packets, interfaces, and other elements are plain observable entities.
Understanding from an application point of view.
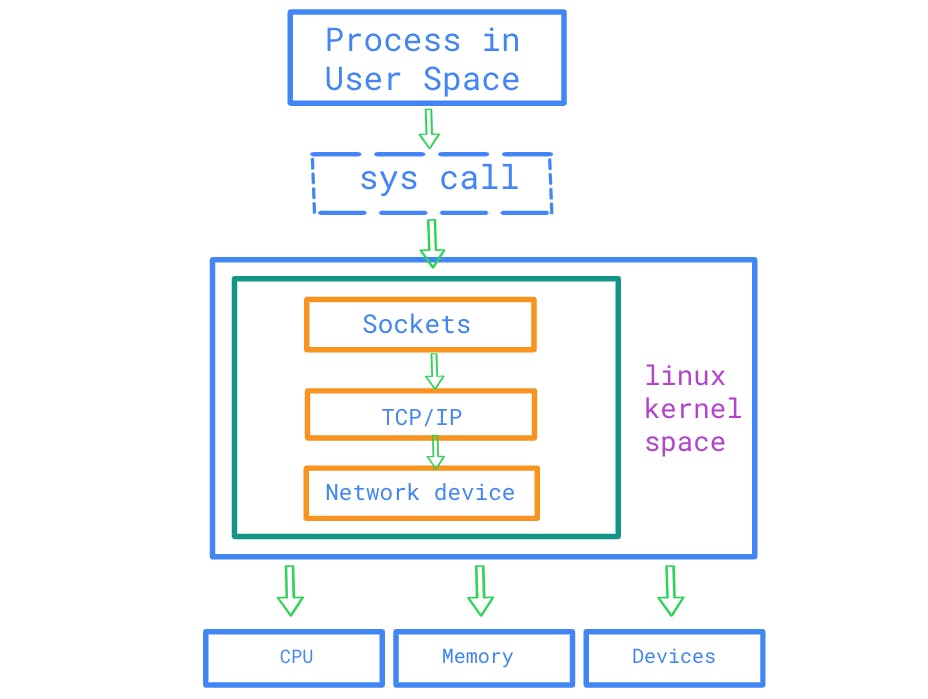
As app developers, we know that every process within an application, at some point, interacts with the Linux kernel. While we write code in user space, certain actions like file operations, memory allocation, network communication, and socket handling often involve hardware interaction. User space isn't equipped to manage these tasks on its own; it relies on the kernel for assistance.

Additionally, in recent years, as cloud-native practices have gained traction, we can see a paradigm shift from having a few large VMs to adopting numerous distributed smaller containers. Organizations are increasingly inclined to use container-based technologies, and developers are deploying complex code more frequently than ever before, while the kernel remains unchanged. Therefore, to keep up with the pace of these evolving applications, situations arise where developers aim to introduce new changes or functionalities within the kernel based on their specific requirements. Moreover, gaining observability into the message packets sent among microservices or within user-kernel space is crucial to understand as it helps in troubleshooting issues from the ground up. Thus, over time it leads to a demand for innovation in the kernel.

However, adding any new features to the Linux kernel is challenging because of the following reasons:
It requires engaging directly with the kernel code which is usually a complex and time-intensive process. As the cycle starts from the creation of a patch that then undergoes multiple stages of approval from the community and maintainers, the process further entails complex development and testing. Even if a feature successfully clears all these hurdles and is available upstream, it could still take a considerable amount of time before it's accessible to end users on their distributions at a significant scale.
Another approach to modify the kernel is through kernel modules which enable us to load or unload specific components based on our needs. While this modular method provides the advantage of quicker customization compared to directly altering kernel code, some production systems disable dynamic module loading for security reasons. As kernel holds a privileged status, it's important to recognize the risks associated with modules, if originating from untrusted sources that could potentially result in system crashes due to bugs or harbour malicious activities.

The above context, leaves us with the question, "How can we effectively enhance kernel capabilities?" Acknowledging that there is no better place than the kernel itself to implement networking, security, and observability functionality due to its privileged ability to oversee and control the entire system.
effective solution.

To address the above set of problems, eBPF emerges as one of the effective solutions that instantly makes the kernel programmable dynamically with substantially low overhead. In simpler terms, we can write customized programs and virtually load or unload them within the kernel space without affecting other ongoing processes. These programs are hooked with various kernel events, triggered by nearly all syscalls. Events can be related to the network (socket opening/closing, disk reading/writing), functions in user space, kernel tracepoint and various others.
Note: By default, processes aiming to load eBPF programs into the Linux kernel must possess root privileges. If unprivileged access is enabled it permits unprivileged processes to load specific eBPF programs but with restricted functionality and kernel access.
Moreover, eBPF-based tools offer the advantage of avoiding system reboots to view new functionalities. This helps the observability and security tools instantly provide visibility into ongoing machine activities without interruption even if there are multiple nodes.
A typical flow of an eBPF program
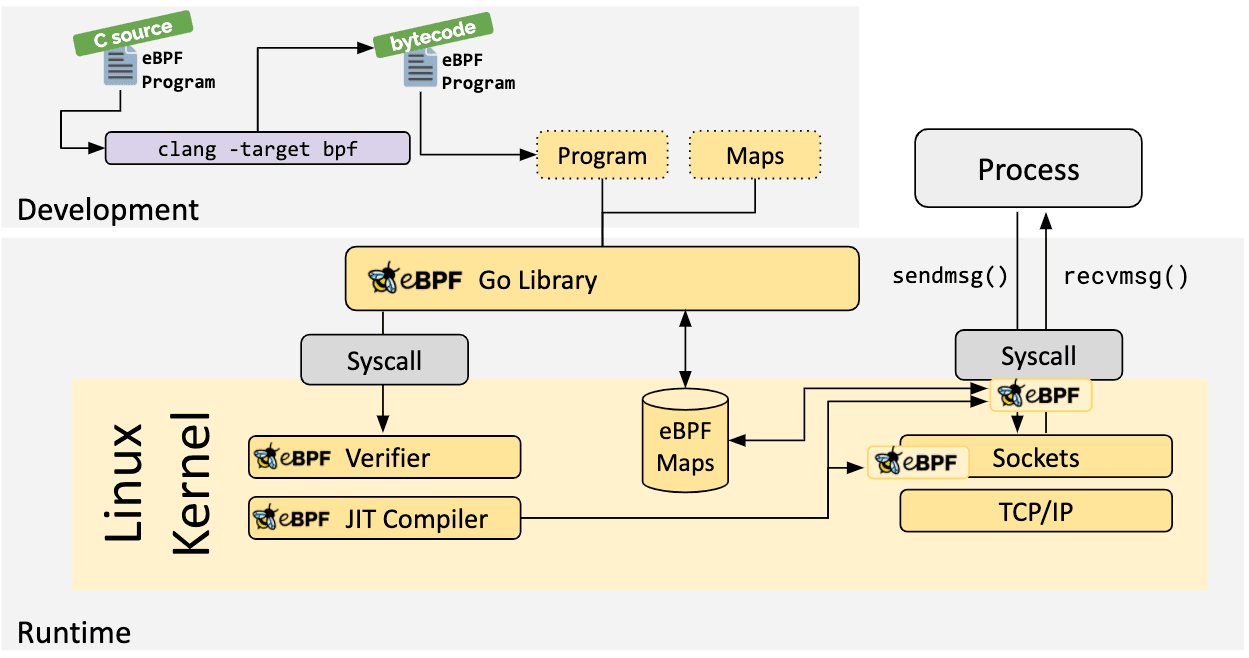
Initially, programs written in various languages in the user space are compiled into eBPF bytecode using an existing eBPF toolchain (like clang, etc.) before being loaded into the kernel.
Given that we're dealing with the kernel—a privileged component—security becomes a paramount consideration. As a result, every loaded program undergoes verification by the eBPF verifier, which performs a range of checks on the generated bytecode to ensure that every instruction is safe. Some of the checks include :
Programs must have the necessary privileges to be loaded into the kernel.
Programs must always run to completion and will not crash or harm the system.
The program must satisfy the size requirements of the system and should only access the memory that they are authorized to interact with.
The eBPF verifier also aids in validating the license and various types of helper functions used in the process. Ultimately, if the verification of a program fails, the verifier assists in generating logs that illustrate how it reached the conclusion that the program is invalid.
The translated bytecode is fairly low-level, although it hasn't reached the point of being executed in the kernel as machine code yet. Therefore, following verification, eBPF typically utilizes a Just-In-Time (JIT) compiler to convert the eBPF bytecode into native machine code. This adaptation enables the bytecode to execute more efficiently on the target CPU, resulting in improved performance.
The eBPF program is then hooked to specific events, such as network packet arrival, hitting some particular point in kernel code, system calls, and others. Thus, whenever any of the hooked events occur, it triggers the associated eBPF program to be executed within the kernel. These programs then perform specific actions, including but not limited to, sharing data with other eBPF programs, logging to user space, storing or modifying the data, or taking other actions based on the events.
Once the eBPF program has fulfilled its purpose, it is first detached from the event that triggers it, followed by removal from the kernel accordingly and the release of any allocated resources, for security reasons.
Some other key eBPF components
eBPF Maps
In the beginning, we discussed some groundbreaking additions that make eBPF highly efficient compared to its classic predecessor. eBPF maps can be considered one of those additions that facilitate efficient and controlled data sharing.
They are different types of data structures used to share data among multiple eBPF programs or to enable communication between applications in user space and the eBPF code running in the kernel. They can be accessed either from the kernel or user space through system calls. These maps are created during the loading process of an eBPF program, which occurs when the program is attached to a specific hook point in the kernel.
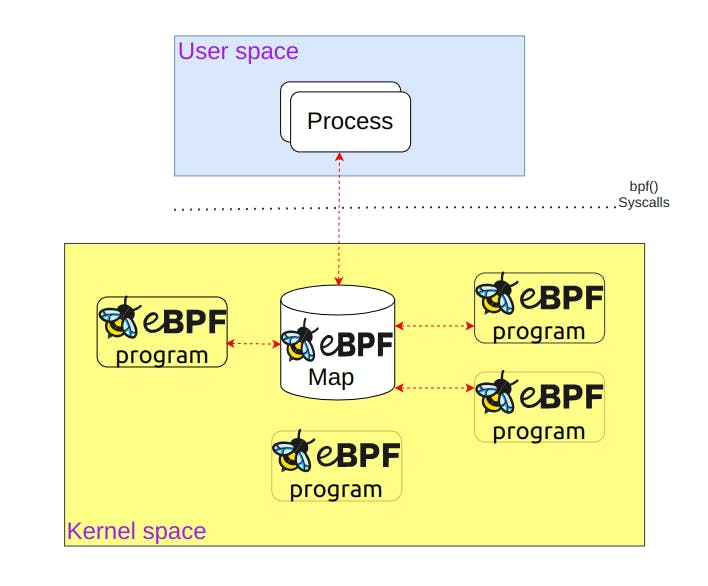
Some of the tasks that are usually performed by maps include:
User space writing configuration information for retrieval by an eBPF program.
Storing the state of the eBPF program for later retrieval by another eBPF program or a future run of the same program.
An eBPF program writes results or metrics into a map, which can be retrieved by the user space app responsible for presenting the results.
Helper functions
Directly calling kernel functions from eBPF programs is not allowed (unless they are registered as kfuncs). However, eBPF offers several predefined helper functions that allow programs to efficiently and safely access kernel information and perform various operations. Helper functions are integral to the eBPF program itself, distinct from the eBPF verifier or eBPF maps.
There are numerous helper functions are available, for specific program types. Some frequently used ones include:
get current process id and thread id,
get current kernel time and date
Looks, update or delete an element in a map.
get random number, etc.
Importance of eBPF in cloud native observability

When discussing a typical Kubernetes cluster, where numerous services from a user-space application are containerized and run in various pods, it becomes clear that both containers and pods on the host share a common kernel. Additionally, it's important to note that when applications within these pods perform actions involving hardware interaction—such as reading/writing to a file or sending/receiving network traffic, or when Kubernetes create/delete containers—the kernel actively plays a role in the process.
Therefore, it is important to shift our focus from observability at the pod level to the kernel level using eBPF programs. These programs help us instrument almost any aspect of kernel operations and observe all activities on the host system at a granular level. eBPF proves to be incredibly valuable for a wide range of purposes, including collecting various metrics, developing monitoring tools, and implementing various types of tracing mechanisms.