An approach to Monitoring and Observability in a Cloud Native way...



In the early days, it was common to solely check the health of the servers. However, the advent of cloud-native technologies has raised concerns about keeping track of health at a service level, which resulted in modern applications becoming increasingly reliable yet concurrently more complex. Due to the increasing popularity of the cloud native-based approach, It has been seen over the last decade that the majority of the applications are transitioning from monoliths to a microservice-based architecture where applications are built with many languages, frameworks, serverless functions, data stores, and more, all running in clouds or on-premise datacentres, etc.
So to stay competitive developers are deploying codes faster and more frequently thus compounding the overall complexity of the application. Although these complexities are essential, they can pose challenges in understanding the underlying processes when problems occur. In this type of architecture, there is a significant probability that a given service may invoke another service, which in turn may further call multiple additional services to execute a user request, thus making it crucial to closely watch our application at every possible service to be stable. To achieve this stability for our distributed system, it is essential to effectively implement monitoring and observability best practices.
Although monitoring and observability are intertwined, they are not interchangeable. So it is essential to clarify the concepts that what exactly are monitoring and observability. Are they synonymous or distinct? If uncertain, let us try to examine how these practices can be implemented to enhance the stability of our application.
Monitoring and Observability...
Rather than delving into multiple definitions, grasping the fundamental concept of monitoring and observability through a simple example is important. Let's consider a scenario where you have a bank account and attempt to withdraw funds from an ATM. However, you encounter difficulty in completing the withdrawal. In this case, monitoring can be likened to your awareness that you are unable to withdraw due to known or expected indicators such as an overdrawn account.
On the other hand, observability can be comprehended as providing the information received through monitoring and additional insights into the underlying causes. In the context of our previous example, observability goes deeper instead of simply notifying you of the inability to withdraw funds, It provides a broader perspective by offering detailed transaction history or any other specific reasons for the issue. Thereby allowing you to understand the precise factors hindering the completion of the transaction and how to fix them.
Monitoring assumes a pivotal role in constructing dashboards and facilitating alerting mechanisms from the anticipated outcomes. Nevertheless, predicting outcomes in intricate, distributed applications proves challenging due to the non-linear and unanticipated nature of production failures. To illustrate this point, let's consider the example of a RAM failure where it is already acknowledged that failure is likely to happen when the capacity reaches a specific percentage, denoted as 'x'. Monitoring primarily addresses these known failures, which may be insufficient when dealing with a distributed architecture.
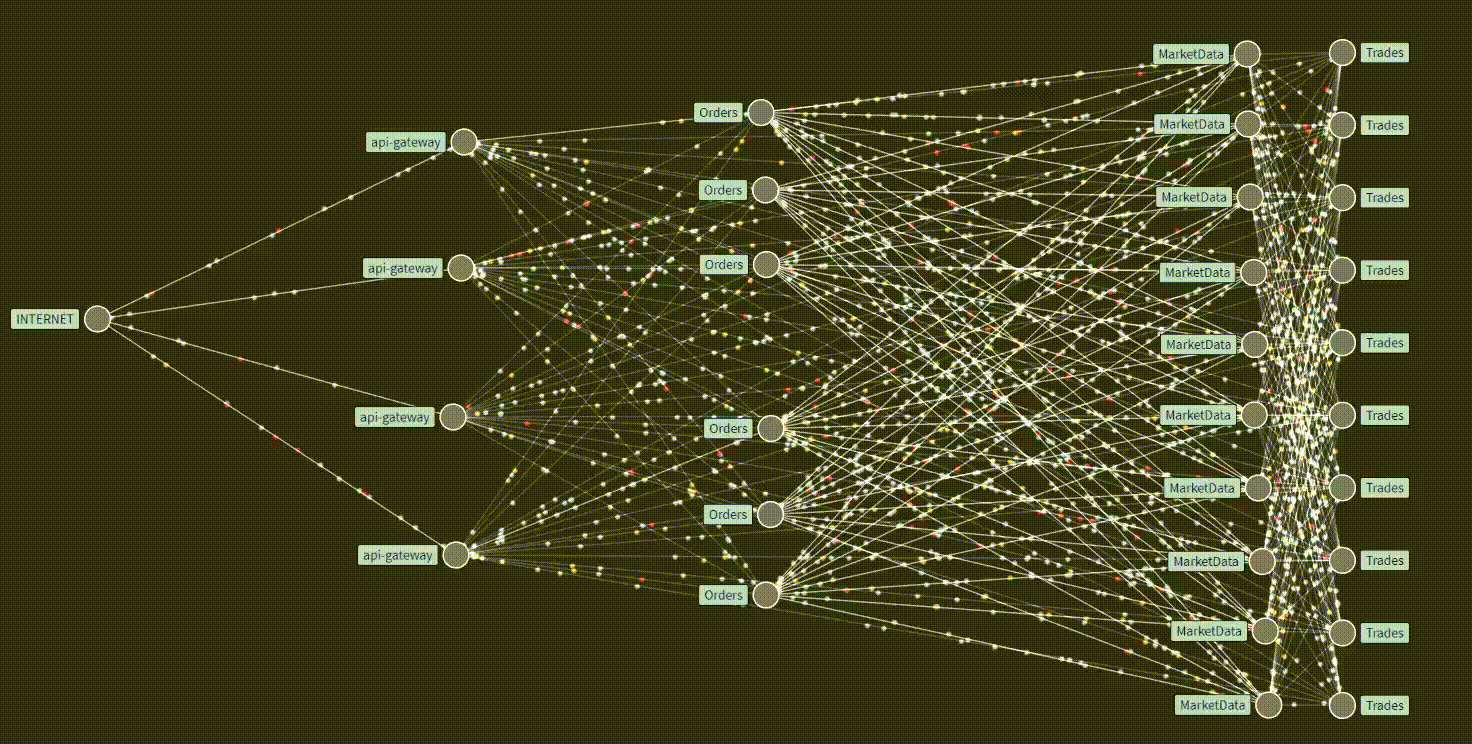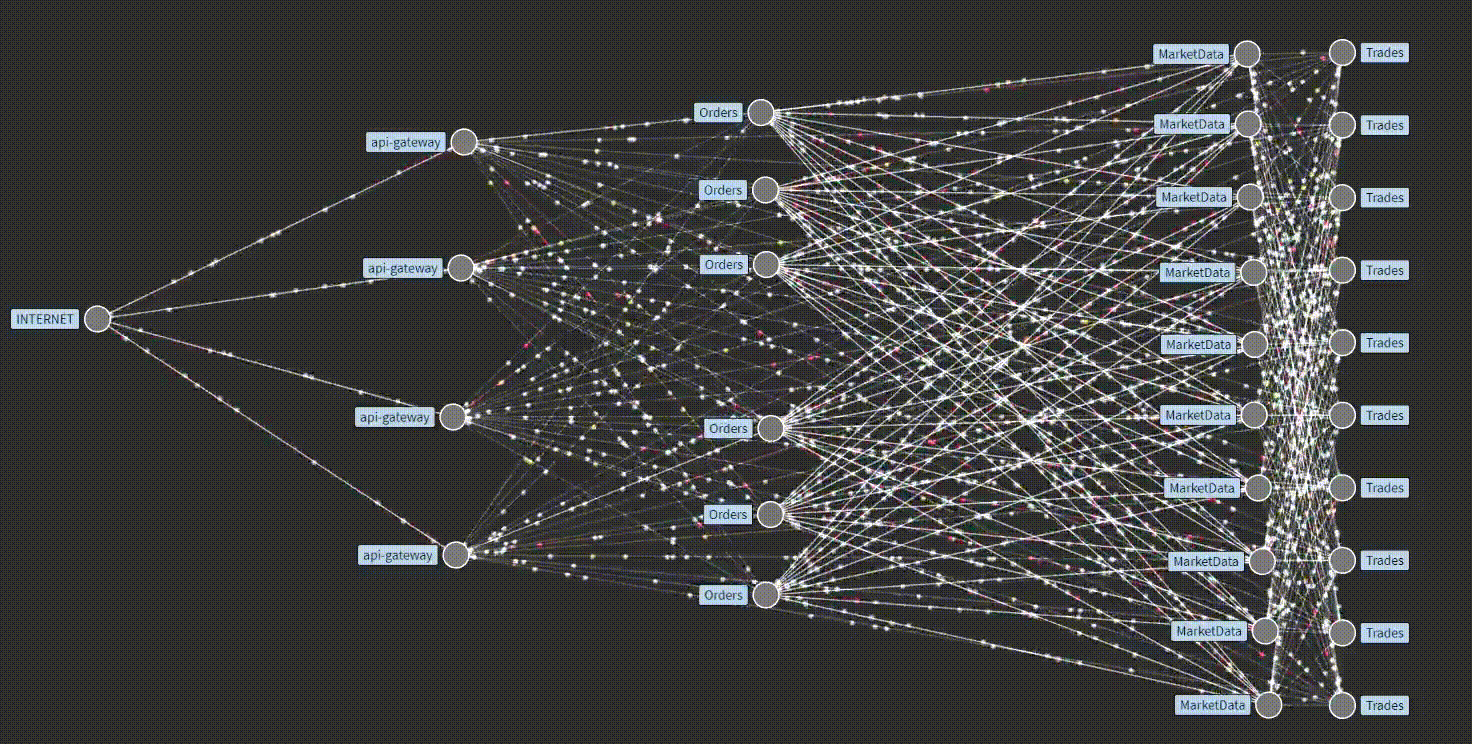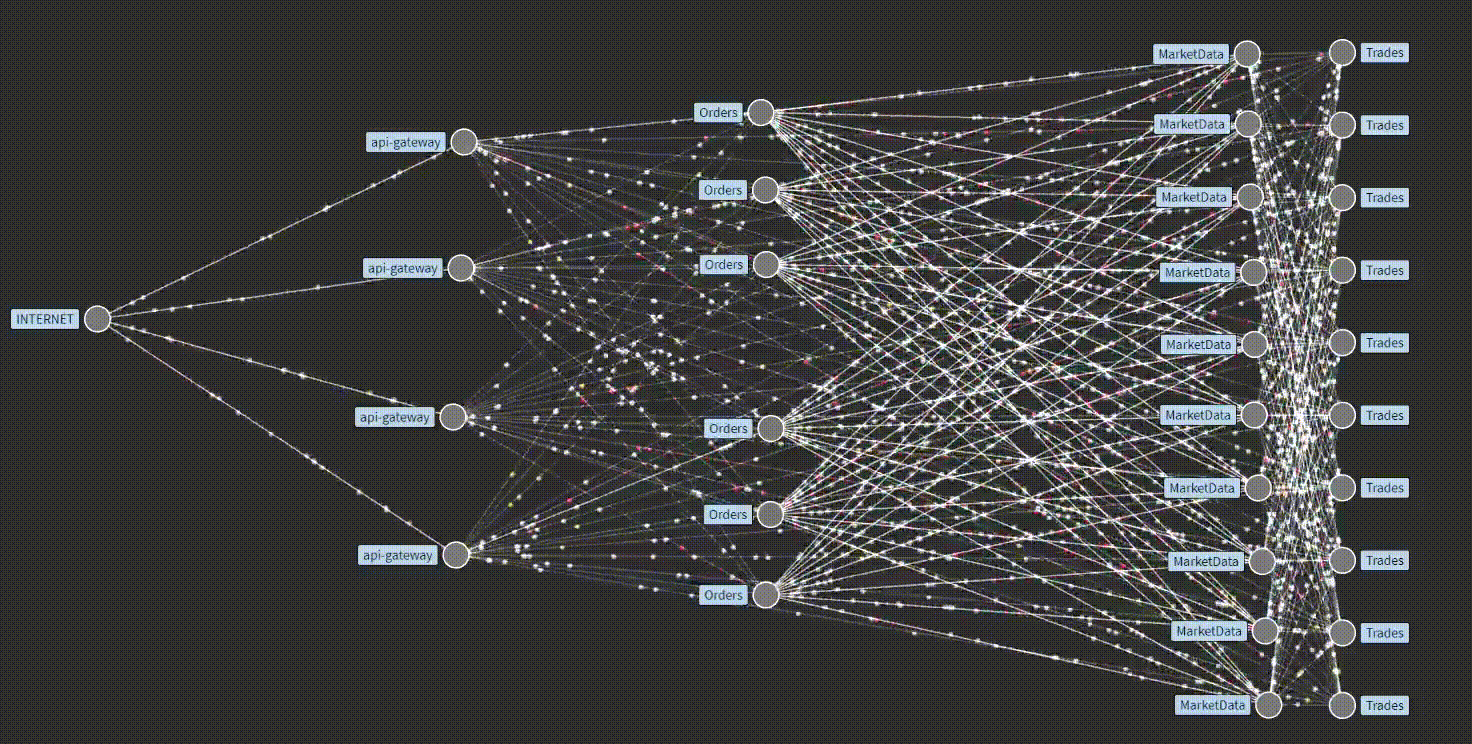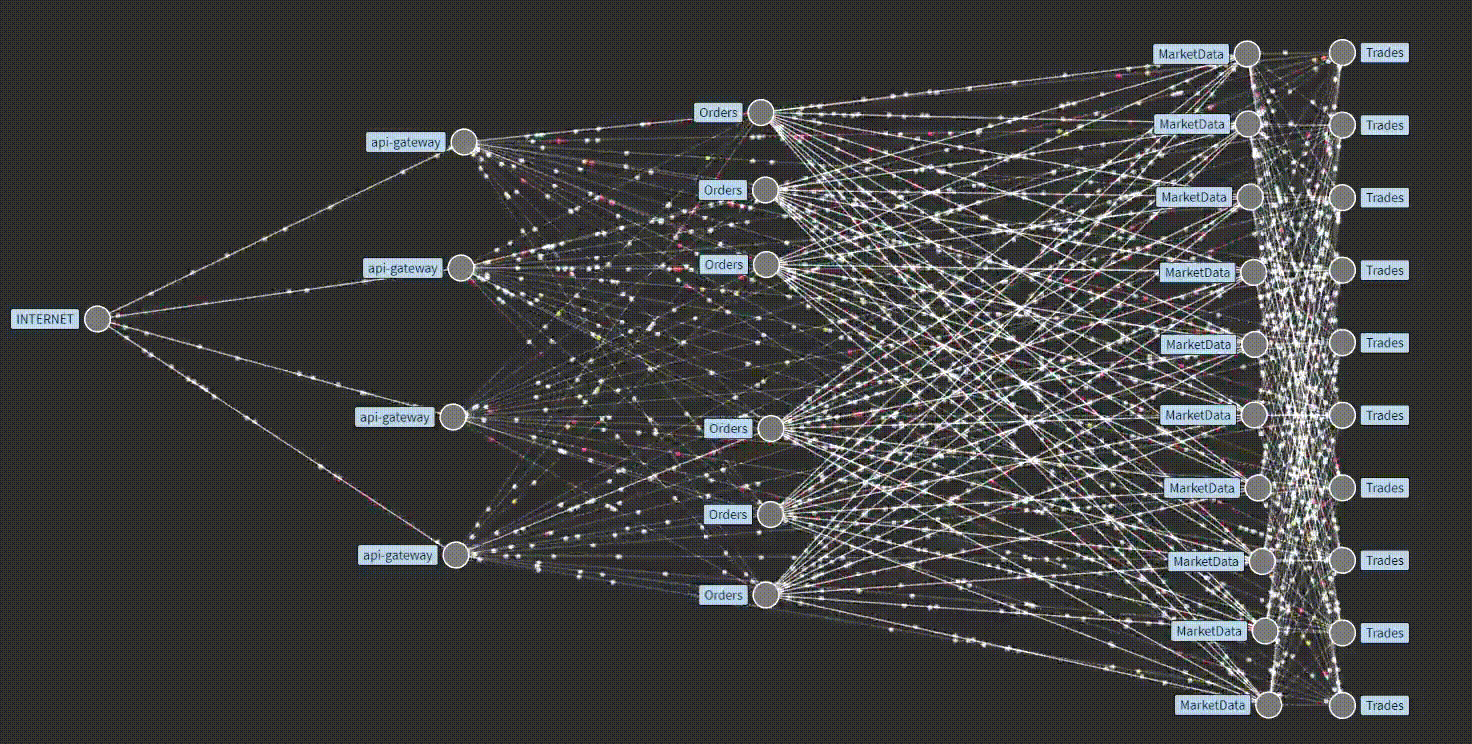
In contrast to monitoring, Observability (abbreviated as "o11y" ) does not revolve solely around predetermining failures. The underlying concept here is to move beyond mere monitoring and instead seek a comprehensive understanding of the system failure. This involves collecting extensive data from every possible service point within the distributed system for example, how service-to-service interaction takes place internally, how data flows with time around these services, and what output we get from a particular service, etc, which can then be utilized later for specific analysis, which ultimately contribute to overall enhanced stability.
Henceforth, it can be inferred that at present solely relying on monitoring is not the optimal solution. Instead, it is imperative to perceive monitoring as a subset of a broader perspective known as Observability, which is the ability to understand the state of our system. Therefore our inquiry should not revolve around the comparison of Observability versus Monitoring. Rather, it should focus on determining the most suitable approach for our system, optimizing it effectively, and establishing a foundation that allows us to confidently rely on our services.
How do we Observe the application?
Now we have established the importance of o11y for our system or services. However, our focus now shifts towards the question of how to effectively harness observability. Are there specific protocols to stick with? and other related questions.
Our prior discussion emphasized the significance of data emitted from various services and functions within our application for observability. These emitted data are collected, analyzed, and subsequently utilized to undertake appropriate actions for issue resolution. Now, let us delve deeper into the nature of these collected data. Generally, they are broadly categorized as Traces, Metrics, Logs, and other related data. These traces, Metrics, and Logs are usually referred to as the three pillars of o11y, through which we could comprehensively understand our service.

🪵Logs are easily comprehensible, particularly for individuals with a developer background, even those in the early stages of their programming journey. During the process of writing a basic addition function, logs are commonly employed to verify the expected sum and aid in debugging errors at a granular level. For instance, while working with JavaScript we must have used Console.log(), in Go we have used "fmt.Print", and also other programming languages offer their logging libraries for this purpose.
In summary, logs consist of timestamped text records, which can be either structured or unstructured. They contain detailed debugging and diagnostic information, such as input/output operations, operation outcomes, and accompanying metadata specific to each operation, aiding in the thorough analysis and understanding of software behavior. Nevertheless, logs in isolation are insufficient to provide us with comprehensive insights into the performance of a function or any other specific component within our distributed application.
📏 Metrics can be defined as measurements or aggregations about specific services that are captured during runtime. They offer valuable quantitative data about various aspects of a system's performance. Commonly used metric endpoints include System Error Rate, requests per second (RPS), p99 latency, p95 latency, p50 latency, CPU utilization, and more. These metrics provide valuable insights into the behavior and efficiency of the service.
🕵️Traces provide a structured means of observing the internal workings of an application when a request is made. They offer a comprehensive view of the path traversed by a request within the application, including the invocation of various services. Traces are derived from diverse sources such as processes, services, virtual machines (VMs), and data centers. While applicable to any system, traces yield additional benefits when applied to distributed systems.
Traditionally, logs and metrics were the primary means of observing applications, with traces being considered a niche approach. However, over time, the importance of tracing has become increasingly recognized. It is now acknowledged as a significant approach for comprehending application behavior at its core, identifying underlying causes, detecting malfunctioning services, pinpointing delays, and facilitating various troubleshooting approaches. In essence, traces are like detectives for applications, assisting in the investigation of unexpected failures.

The prevalent notion within the tech revolves around Traces, Metrics, and Logs being the three pillars of the o11y landscape but it's more beyond these three things like Continuous profiling, etc. Therefore, it is imperative to shift our perspective and view Logs, Metrics, and Traces not as separate entities, but rather as a single entity.
Now, let us focus on the next set of questions: Are these data collected using a predefined data structure similar to other programming languages? Do applications inherently emit these data by default? The response to this question can be summarized as a combination of "yes" and "slightly no." Is there an alternative approach or specific standards to adhere to? However, the straightforward answer to most of these questions lies in OpenTelemetry, which is a unified Observability framework that follows a set of standards that any tool can be instrumented with to emit and collect data from the distributed system. So the concept of Otel is extensively explained in the linked blog post.